국내 10여개 기관에 배포해 최소 150억원 수입대체 효과
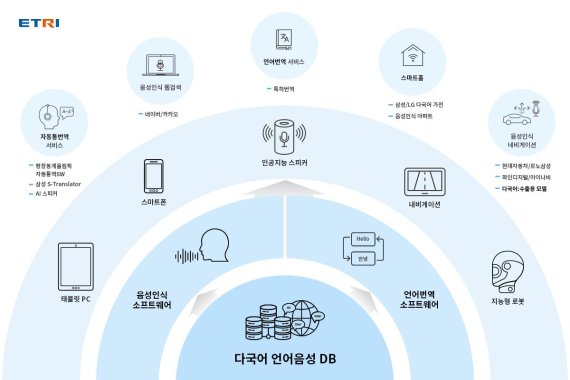
한국전자통신연구원(ETRI)이 국내 첫 태국어, 말레이어, 인도네시아어의 음성 데이터베이스와 영어대역문장 DB를 일반에 배포한다. 아랍어 및 베트남어도 함께 배포하는데 기존보다 데이터양을 대폭 늘렸다. 이로써 음성인식 및 번역엔진 해외 의존도를 줄이고 해당 언어를 활용한 다양한 서비스 개발에 큰 도움이 될 것으로 예상된다.
이 음성 DB는 최근 인기 있는 인공지능(AI) 스피커, 내비게이션, 사물인터넷(IoT) 등 음성인식 및 번역 SW개발에 기초가 되는 자료다.
국내 관련 업체들은 ETRI가 제공하는 자료를 받아 DB구축 비용을 대폭 절감할 수 있다. 해외 업체로부터 DB를 구입하는 경우, 언어 당 1~2억 원 정도의 비용이 소요된다. 하지만 ETRI는 해외 DB 가격 대비 5% 수준에서 제공할 예정이다. 국내 10개 기관에 배포할 경우, 최소 150억원의 수입대체 효과를 얻을 수 있다. 따라서 가능한 품질이 좋고 많은 언어의 DB를 구축하는 것이 서비스 다양화와 고부가가치 서비스기술 창출의 핵심이라 할 수 있다.
윤승 ETRI 음성지능연구그룹 박사는 "이 DB를 활용해 언어음성기술을 개발할 경우, 다양한 외국 신규시장 진출 및 국가 경쟁력 강화에 큰 기여를 할 것"이라고 전망했다.
그동안 DB를 확보하는 과정에 여러 장벽이 있었다. 해외 업체로부터 외국어 음성 DB를 구입할 수 있지만 비용이 많이 든다. 그마저도 관련 자료가 없는 나라의 언어는 자체적으로 수집하는 수밖에 없었다.
이에 ETRI가 태국어, 말레이어, 인도네시아어, 아랍어, 베트남어 '대화체 음성DB 200만가지 번역'과 영어-태국어, 영어-말레이어, 영어-인도네시아어, 영어-아랍어, 영어-베트남어 '대화체 번역 DB 300만 문장'을 배포한다. 태국어, 말레이어, 인도네시아어 자료는 국내 최초로 제공되며 아랍어 및 베트남어는 ETRI 기존 자료에 데이터양을 늘려 배포한다.
특히 이번 DB는 최대한 많은 사람들의 언어 데이터를 얻기 위해 크라우드 소싱(Crowd sourcing) 기법을 도입했다. 포인트를 제공해 일반 사용자들의 참여를 유도한 결과, 총 2만5000여 명이 발화에 참여했으며 같은 예산으로 기존보다 최대 8배 많은 데이터를 수집할 수 있었다.
단순히 데이터 양만 늘린 것이 아니라 높은 정확도까지 확보했다. 외부 감리 업체 측정 결과 99% 이상의 높은 품질을 인증 받았다. 기존보다 더욱 많은 양을 축적한 데이터를 토대로 집단 지성에 의한 검증 시스템을 도입했기 때문이다.
그간 ETRI는 외국 기술 잠식을 차단하고 국내 기업들의 관련 기술 수출 증진을 위해 지능형 언어음성 데이터를 꾸준히 확보해왔다. 2011년부터 한·영·일·중 등 다국어 언어음성DB를, 2014년에는 프랑스어, 2015년에는 독일어, 러시아어, 아랍어, 베트남어를 구축 및 배포한 바 있다.
현재까지 삼성전자, LG전자, KT, 네이버, 카카오, 엔씨소프트, 보이스웨어, 셀바스AI, 시스트란 인터내셔널, 솔트룩스 등 국내 60개 기관에 367건의 DB를 배포하며 총 550억원에 해당하는 비용 절감 성과를 얻었다.
ETRI가 배포 중인 DB목록은 총 45종으로 ETRI 홈페이지에서 쉽게 찾아볼 수 있다. 이번 추가 공개하는 DB도 ETRI 홈페이지를 통해 확인이 가능하다.
monarch@fnnews.com 김만기 기자
※ 저작권자 ⓒ 파이낸셜뉴스, 무단전재-재배포 금지